
![]()
Updated PDF (New 2022) Actual Microsoft DP-203 Exam Questions
Verified DP-203 Exam Dumps PDF [2022] Access using CertkingdomPDF
Microsoft DP-203 Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
| Topic 7 |
|
| Topic 8 |
|
| Topic 9 |
|
| Topic 10 |
|
| Topic 11 |
|
Schedule exam
Languages: English, Chinese (Simplified), Japanese, Korean
Retirement date: none
This exam measures your ability to accomplish the following technical tasks: design and implement data storage; design and develop data processing; design and implement data security; and monitor and optimize data storage and data processing.
NEW QUESTION 41
You are building an Azure Analytics query that will receive input data from Azure IoT Hub and write the results to Azure Blob storage.
You need to calculate the difference in readings per sensor per hour.
How should you complete the query? To answer, select the appropriate options in the answer are a.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/stream-analytics-query/lag-azure-stream-analytics
NEW QUESTION 42
You have an Azure subscription that contains the following resources:
* An Azure Active Directory (Azure AD) tenant that contains a security group named Group1.
* An Azure Synapse Analytics SQL pool named Pool1.
You need to control the access of Group1 to specific columns and rows in a table in Pool1 Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area.
NOTE: Each appropriate options in the answer area.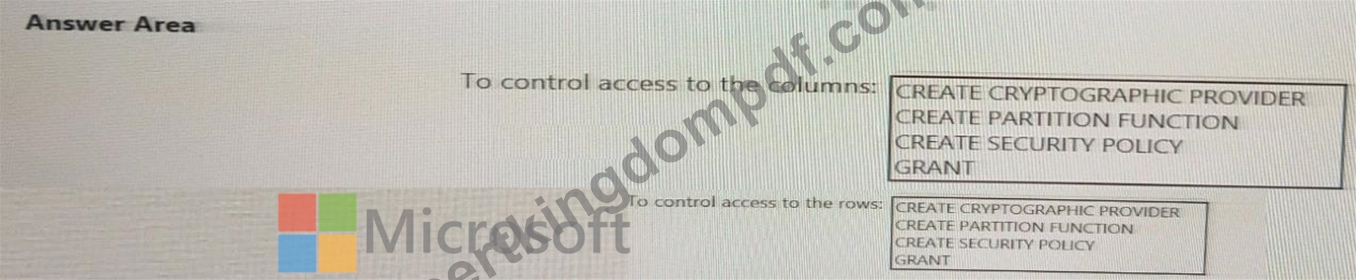
Answer:
Explanation: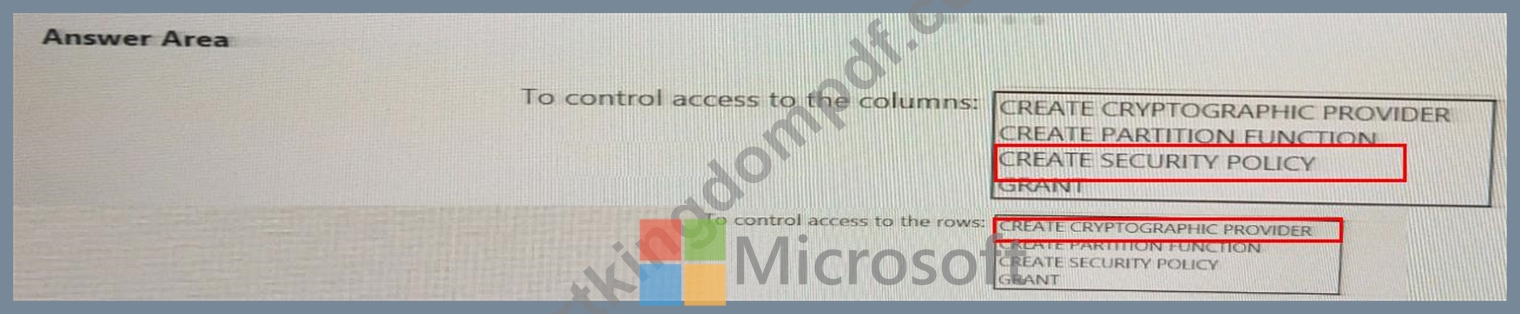
NEW QUESTION 43
You need to trigger an Azure Data Factory pipeline when a file arrives in an Azure Data Lake Storage Gen2 container.
Which resource provider should you enable?
- A. Microsoft.EventHub
- B. Microsoft.EventGrid
- C. Microsoft.Sql
- D. Microsoft-Automation
Answer: B
NEW QUESTION 44
You are implementing Azure Stream Analytics windowing functions.
Which windowing function should you use for each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.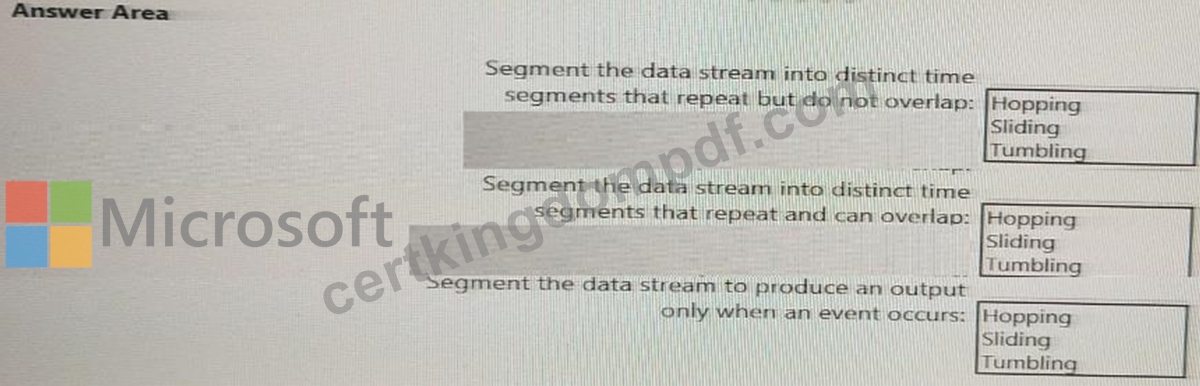
Answer:
Explanation:
NEW QUESTION 45
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements:
Ingest:
Access multiple data sources.
Provide the ability to orchestrate workflow.
Provide the capability to run SQL Server Integration Services packages.
Store:
Optimize storage for big data workloads.
Provide encryption of data at rest.
Operate with no size limits.
Prepare and Train:
Provide a fully-managed and interactive workspace for exploration and visualization.
Provide the ability to program in R, SQL, Python, Scala, and Java.
Provide seamless user authentication with Azure Active Directory.
Model & Serve:
Implement native columnar storage.
Support for the SQL language
Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.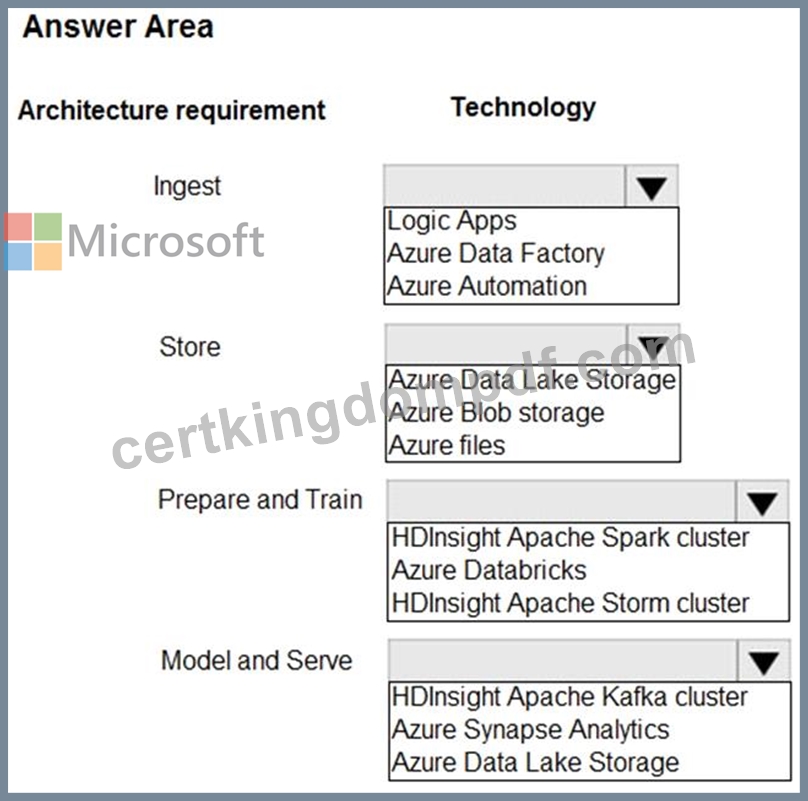
Answer:
Explanation:
NEW QUESTION 46
You need to implement the surrogate key for the retail store table. The solution must meet the sales transaction dataset requirements.
What should you create?
- A. a table that has a FOREIGN KEY constraint
- B. a table that has an IDENTITY property
- C. a user-defined SEQUENCE object
- D. a system-versioned temporal table
Answer: B
Explanation:
Scenario: Implement a surrogate key to account for changes to the retail store addresses.
A surrogate key on a table is a column with a unique identifier for each row. The key is not generated from the table data. Data modelers like to create surrogate keys on their tables when they design data warehouse models. You can use the IDENTITY property to achieve this goal simply and effectively without affecting load performance.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-identity This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
NEW QUESTION 47
You implement an enterprise data warehouse in Azure Synapse Analytics.
You have a large fact table that is 10 terabytes (TB) in size.
Incoming queries use the primary key SaleKey column to retrieve data as displayed in the following table: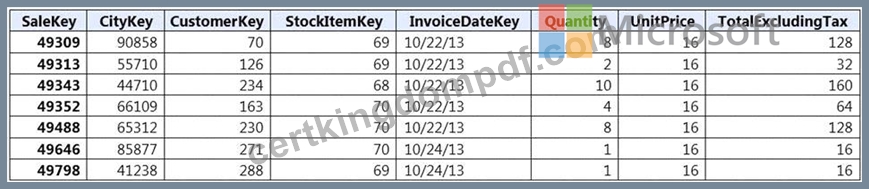
You need to distribute the large fact table across multiple nodes to optimize performance of the table.
Which technology should you use?
- A. hash distributed table with clustered index
- B. heap table with distribution replicate
- C. round robin distributed table with clustered Columnstore index
- D. hash distributed table with clustered Columnstore index
- E. round robin distributed table with clustered index
Answer: D
Explanation:
Explanation
Hash-distributed tables improve query performance on large fact tables.
Columnstore indexes can achieve up to 100x better performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/sql/relational-databases/indexes/columnstore-indexes-query-performance
NEW QUESTION 48
You plan to create an Azure Data Lake Storage Gen2 account
You need to recommend a storage solution that meets the following requirements:
* Provides the highest degree of data resiliency
* Ensures that content remains available for writes if a primary data center fails What should you include in the recommendation? To answer, select the appropriate options in the answer area.
Answer:
Explanation:
See the answer in explanation.
Explanation
Answer is below
NEW QUESTION 49
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are designing an Azure Stream Analytics solution that will analyze Twitter dat a.
You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only once.
Solution: You use a tumbling window, and you set the window size to 10 seconds.
Does this meet the goal?
- A. No
- B. Yes
Answer: B
Explanation:
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. The following diagram illustrates a stream with a series of events and how they are mapped into 10-second tumbling windows.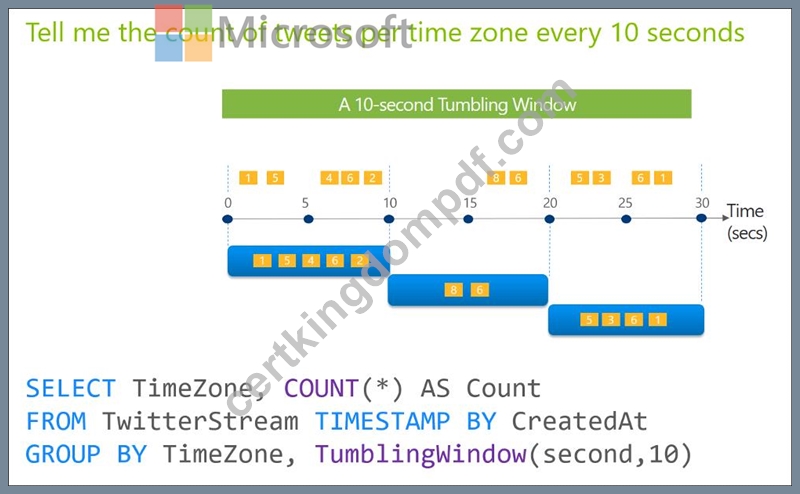
Reference:
https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
NEW QUESTION 50
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this scenario, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have an Azure Storage account that contains 100 GB of files. The files contain text and numerical values.
75% of the rows contain description data that has an average length of 1.1 MB.
You plan to copy the data from the storage account to an Azure SQL data warehouse.
You need to prepare the files to ensure that the data copies quickly.
Solution: You modify the files to ensure that each row is more than 1 MB.
Does this meet the goal?
- A. No
- B. Yes
Answer: A
Explanation:
Explanation
Instead modify the files to ensure that each row is less than 1 MB.
References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/guidance-for-loading-data
NEW QUESTION 51
You have an Azure subscription that contains the following resources:
* An Azure Active Directory (Azure AD) tenant that contains a security group named Group1.
* An Azure Synapse Analytics SQL pool named Pool1.
You need to control the access of Group1 to specific columns and rows in a table in Pool1 Which Transact-SQL commands should you use? To answer, select the appropriate options in the answer area.
NOTE: Each appropriate options in the answer area.
Answer:
Explanation:
NEW QUESTION 52
You need to implement an Azure Synapse Analytics database object for storing the sales transactions dat a. The solution must meet the sales transaction dataset requirements.
What solution must meet the sales transaction dataset requirements.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.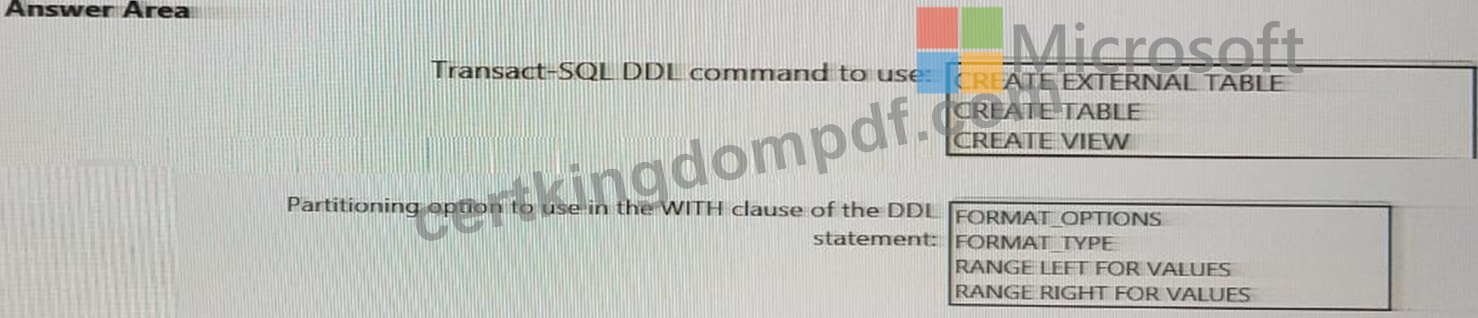
Answer:
Explanation: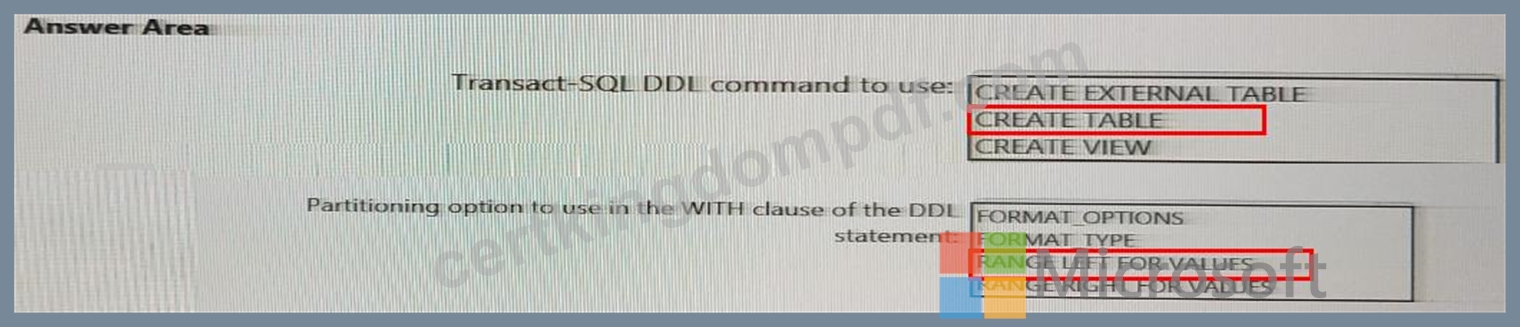
NEW QUESTION 53
You have an Azure data factory.
You need to ensure that pipeline-run data is retained for 120 days. The solution must ensure that you can query the data by using the Kusto query language.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-using-azure-monitor
NEW QUESTION 54
You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.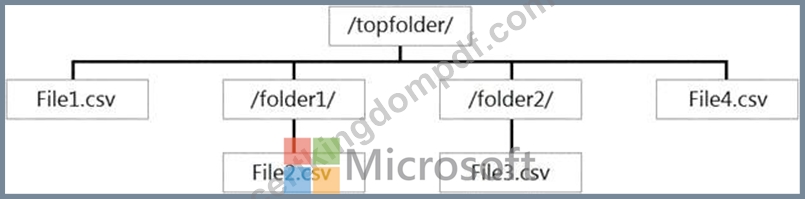
You create an external table named ExtTable that has LOCATION='/topfolder/'.
When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
- A. File1.csv only
- B. File1.csv, File2.csv, File3.csv, and File4.csv
- C. File2.csv and File3.csv only
- D. File1.csv and File4.csv only
Answer: A
Explanation:
Explanation
To run a T-SQL query over a set of files within a folder or set of folders while treating them as a single entity or rowset, provide a path to a folder or a pattern (using wildcards) over a set of files or folders.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-data-storage#query-multiple-files-or-folders
NEW QUESTION 55
You have an Azure Storage account and a data warehouse in Azure Synapse Analytics in the UK South region.
You need to copy blob data from the storage account to the data warehouse by using Azure Data Factory. The solution must meet the following requirements:
* Ensure that the data remains in the UK South region at all times.
* Minimize administrative effort.
Which type of integration runtime should you use?
- A. Azure-SSIS integration runtime
- B. Self-hosted integration runtime
- C. Azure integration runtime
Answer: C
Explanation:
Explanation
Explanation:
Incorrect Answers:
C: Self-hosted integration runtime is to be used On-premises.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/concepts-integration-runtime
NEW QUESTION 56
You need to design a data storage structure for the product sales transactions. The solution must meet the sales transaction dataset requirements.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.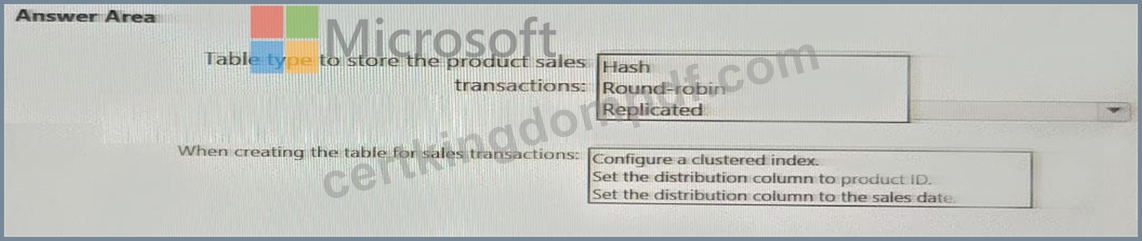
Answer:
Explanation:
NEW QUESTION 57
You have an Azure Stream Analytics query. The query returns a result set that contains 10,000 distinct values for a column named clusterID.
You monitor the Stream Analytics job and discover high latency.
You need to reduce the latency.
Which two actions should you perform? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
- A. Convert the query to a reference query.
- B. Add a pass-through query.
- C. Scale out the query by using PARTITION BY.
- D. Add a temporal analytic function.
- E. Increase the number of streaming units.
Answer: C,E
Explanation:
C: Scaling a Stream Analytics job takes advantage of partitions in the input or output. Partitioning lets you divide data into subsets based on a partition key. A process that consumes the data (such as a Streaming Analytics job) can consume and write different partitions in parallel, which increases throughput.
E: Streaming Units (SUs) represents the computing resources that are allocated to execute a Stream Analytics job. The higher the number of SUs, the more CPU and memory resources are allocated for your job. This capacity lets you focus on the query logic and abstracts the need to manage the hardware to run your Stream Analytics job in a timely manner.
References:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-streaming-unit-consumption
NEW QUESTION 58
You have an Azure Data Lake Storage Gen2 account that contains a JSON file for customers. The file contains two attributes named FirstName and LastName.
You need to copy the data from the JSON file to an Azure Synapse Analytics table by using Azure Databricks. A new column must be created that concatenates the FirstName and LastName values.
You create the following components:
A destination table in Azure Synapse
An Azure Blob storage container
A service principal
Which five actions should you perform in sequence next in is Databricks notebook? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-extract-load-sql-data-warehouse
NEW QUESTION 59
You are planning a streaming data solution that will use Azure Databricks. The solution will stream sales transaction data from an online store. The solution has the following specifications:
* The output data will contain items purchased, quantity, line total sales amount, and line total tax amount.
* Line total sales amount and line total tax amount will be aggregated in Databricks.
* Sales transactions will never be updated. Instead, new rows will be added to adjust a sale.
You need to recommend an output mode for the dataset that will be processed by using Structured Streaming. The solution must minimize duplicate data.
What should you recommend?
- A. Append
- B. Update
- C. Complete
Answer: C
NEW QUESTION 60
You have a SQL pool in Azure Synapse.
You plan to load data from Azure Blob storage to a staging table. Approximately 1 million rows of data will be loaded daily. The table will be truncated before each daily load.
You need to create the staging table. The solution must minimize how long it takes to load the data to the staging table.
How should you configure the table? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.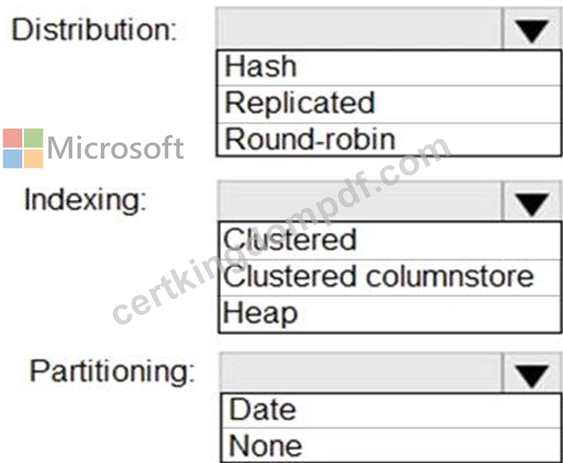
Answer:
Explanation: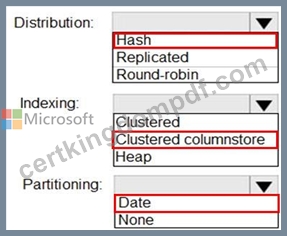
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-partition
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
NEW QUESTION 61
You need to ensure that the Twitter feed data can be analyzed in the dedicated SQL pool. The solution must meet the customer sentiment analytics requirements.
Which three Transaction-SQL DDL commands should you run in sequence? To answer, move the appropriate commands from the list of commands to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.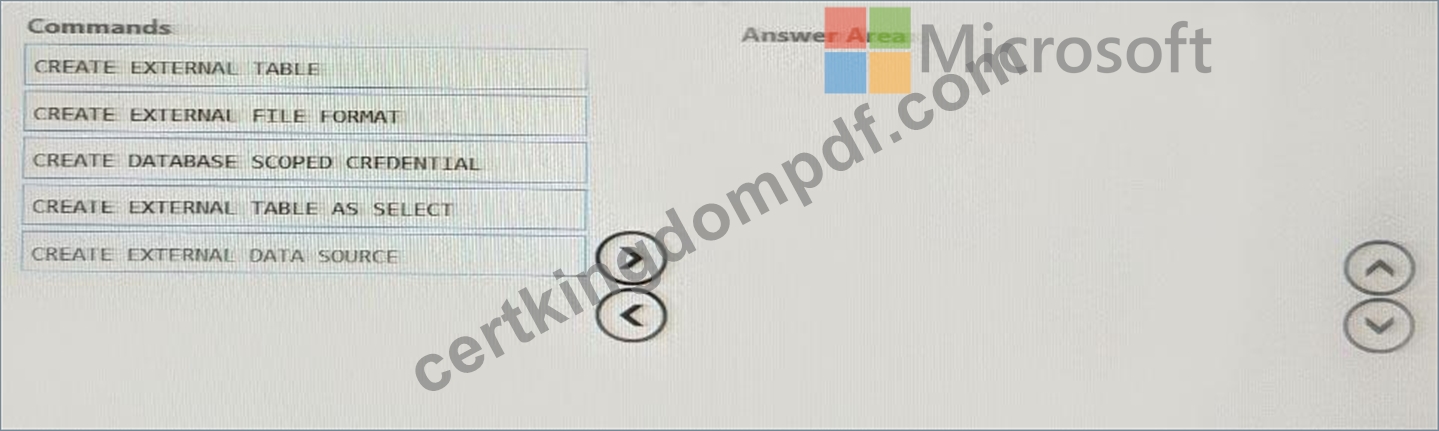
Answer:
Explanation:
NEW QUESTION 62
You need to output files from Azure Data Factory.
Which file format should you use for each type of output? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.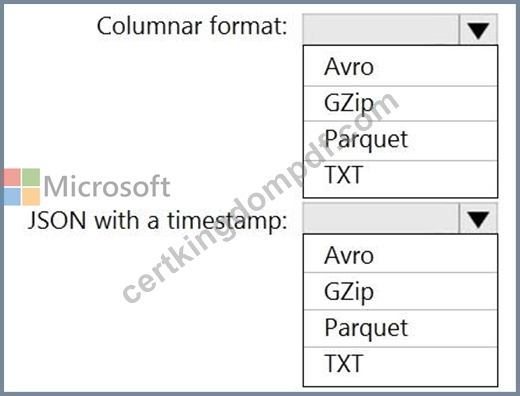
Answer:
Explanation: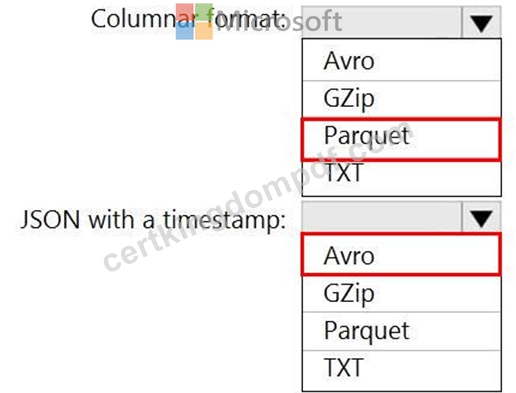
Reference:
https://www.datanami.com/2018/05/16/big-data-file-formats-demystified
NEW QUESTION 63
You are designing a streaming data solution that will ingest variable volumes of data.
You need to ensure that you can change the partition count after creation.
Which service should you use to ingest the data?
- A. Azure Event Hubs Dedicated
- B. Azure Synapse Analytics
- C. Azure Stream Analytics
- D. Azure Data Factory
Answer: A
Explanation:
Explanation
You can't change the partition count for an event hub after its creation except for the event hub in a dedicated cluster.
Reference:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features
NEW QUESTION 64
You need to implement versioned changes to the integration pipelines. The solution must meet the data integration requirements.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation
NEW QUESTION 65
You develop a dataset named DBTBL1 by using Azure Databricks.
DBTBL1 contains the following columns:
* SensorTypeID
* GeographyRegionID
* Year
* Month
* Day
* Hour
* Minute
* Temperature
* WindSpeed
* Other
You need to store the data to support daily incremental load pipelines that vary for each GeographyRegionID.
The solution must minimize storage costs.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.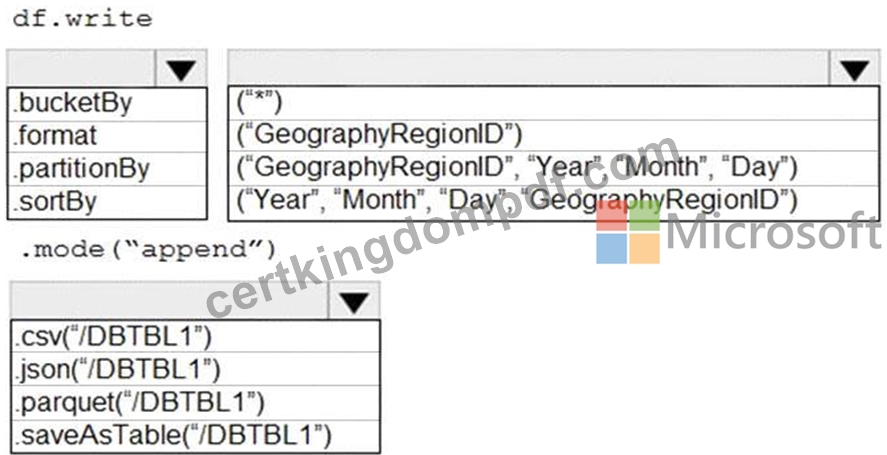
Answer:
Explanation:
Explanation
Graphical user interface, text, application Description automatically generated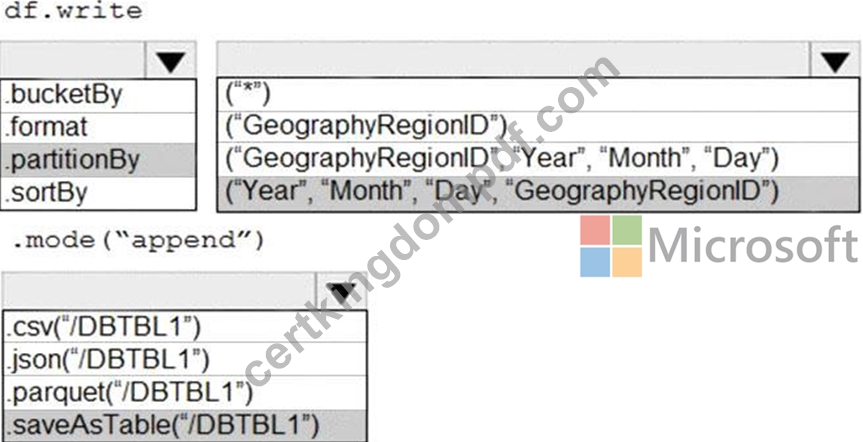
NEW QUESTION 66
......
Try Best DP-203 Exam Questions from Training Expert CertkingdomPDF: https://www.certkingdompdf.com/DP-203-latest-certkingdom-dumps.html
Practice Examples and Dumps & Tips for 2022 Latest DP-203 Valid Tests Dumps: https://drive.google.com/open?id=13ziIf8s3kGCEodVcH7hchBGoKfx9uH2K