
![]()
Professional-Machine-Learning-Engineer Dumps for Pass Guaranteed - Pass Professional-Machine-Learning-Engineer Exam 2024
Professional-Machine-Learning-Engineer Exam Dumps - Try Best Professional-Machine-Learning-Engineer Exam Questions from Training Expert CertkingdomPDF
Google Professional Machine Learning Engineer certification exam is a comprehensive exam that covers a wide range of topics related to machine learning. Professional-Machine-Learning-Engineer exam is designed to test the knowledge and skills of professionals in areas such as data preprocessing, model training, model tuning, model deployment, and monitoring. Professional-Machine-Learning-Engineer exam also covers topics such as machine learning frameworks, data analysis, and data visualization.
NEW QUESTION # 146
You have built a custom model that performs several memory-intensive preprocessing tasks before it makes a prediction. You deployed the model to a Vertex Al endpoint. and validated that results were received in a reasonable amount of time After routing user traffic to the endpoint, you discover that the endpoint does not autoscale as expected when receiving multiple requests What should you do?
- A. Decrease the CPU utilization target in the autoscaling configurations
- B. Use a machine type with more memory
- C. Decrease the number of workers per machine
- D. Increase the CPU utilization target in the autoscaling configurations
Answer: B
NEW QUESTION # 147
You are an ML engineer responsible for designing and implementing training pipelines for ML models. You need to create an end-to-end training pipeline for a TensorFlow model. The TensorFlow model will be trained on several terabytes of structured dat a. You need the pipeline to include data quality checks before training and model quality checks after training but prior to deployment. You want to minimize development time and the need for infrastructure maintenance. How should you build and orchestrate your training pipeline?
- A. Create the pipeline using Kubeflow Pipelines domain-specific language (DSL) and predefined Google Cloud components. Orchestrate the pipeline using Kubeflow Pipelines deployed on Google Kubernetes Engine.
- B. Create the pipeline using TensorFlow Extended (TFX) and standard TFX components. Orchestrate the pipeline using Kubeflow Pipelines deployed on Google Kubernetes Engine.
- C. Create the pipeline using TensorFlow Extended (TFX) and standard TFX components. Orchestrate the pipeline using Vertex AI Pipelines.
- D. Create the pipeline using Kubeflow Pipelines domain-specific language (DSL) and predefined Google Cloud components. Orchestrate the pipeline using Vertex AI Pipelines.
Answer: C
NEW QUESTION # 148
You are developing a Kubeflow pipeline on Google Kubernetes Engine. The first step in the pipeline is to issue a query against BigQuery. You plan to use the results of that query as the input to the next step in your pipeline. You want to achieve this in the easiest way possible. What should you do?
- A. Use the Kubeflow Pipelines domain-specific language to create a custom component that uses the Python BigQuery client library to execute queries
- B. Locate the Kubeflow Pipelines repository on GitHub Find the BigQuery Query Component, copy that component's URL, and use it to load the component into your pipeline. Use the component to execute queries against BigQuery
- C. Write a Python script that uses the BigQuery API to execute queries against BigQuery Execute this script as the first step in your Kubeflow pipeline
- D. Use the BigQuery console to execute your query and then save the query results Into a new BigQuery table.
Answer: D
NEW QUESTION # 149
A Machine Learning Specialist is working with a large company to leverage machine learning within its products. The company wants to group its customers into categories based on which customers will and will not churn within the next 6 months. The company has labeled the data available to the Specialist.
Which machine learning model type should the Specialist use to accomplish this task?
- A. Clustering
- B. Linear regression
- C. Reinforcement learning
- D. Classification
Answer: D
Explanation:
The goal of classification is to determine to which class or category a data point (customer in our case) belongs to. For classification problems, data scientists would use historical data with predefined target variables AKA labels (churner/non-churner) - answers that need to be predicted - to train an algorithm. With classification, businesses can answer the following questions:
* Will this customer churn or not?
* Will a customer renew their subscription?
* Will a user downgrade a pricing plan?
* Are there any signs of unusual customer behavior?
Reference: https://www.kdnuggets.com/2019/05/churn-prediction-machine-learning.html
NEW QUESTION # 150
You are training and deploying updated versions of a regression model with tabular data by using Vertex Al Pipelines. Vertex Al Training Vertex Al Experiments and Vertex Al Endpoints. The model is deployed in a Vertex Al endpoint and your users call the model by using the Vertex Al endpoint. You want to receive an email when the feature data distribution changes significantly, so you can retrigger the training pipeline and deploy an updated version of your model What should you do?
- A. Export the container logs of the endpoint to BigQuery Create a Cloud Function to run a SQL query over the exported logs and send an email. Use Cloud Scheduler to trigger the Cloud Function.
- B. In Cloud Logging, create a logs-based alert using the logs in the Vertex Al endpoint. Configure Cloud Logging to send an email when the alert is triggered.
- C. Use Vertex Al Model Monitoring Enable prediction drift monitoring on the endpoint. and specify a notification email.
- D. In Cloud Monitoring create a logs-based metric and a threshold alert for the metric. Configure Cloud Monitoring to send an email when the alert is triggered.
Answer: C
NEW QUESTION # 151
A credit card company wants to build a credit scoring model to help predict whether a new credit card applicant will default on a credit card payment. The company has collected data from a large number of sources with thousands of raw attributes. Early experiments to train a classification model revealed that many attributes are highly correlated, the large number of features slows down the training speed significantly, and that there are some overfitting issues.
The Data Scientist on this project would like to speed up the model training time without losing a lot of information from the original dataset.
Which feature engineering technique should the Data Scientist use to meet the objectives?
- A. Cluster raw data using k-means and use sample data from each cluster to build a new dataset
- B. Run self-correlation on all features and remove highly correlated features
- C. Normalize all numerical values to be between 0 and 1
- D. Use an autoencoder or principal component analysis (PCA) to replace original features with new features
Answer: C
NEW QUESTION # 152
You are training an LSTM-based model on Al Platform to summarize text using the following job submission script: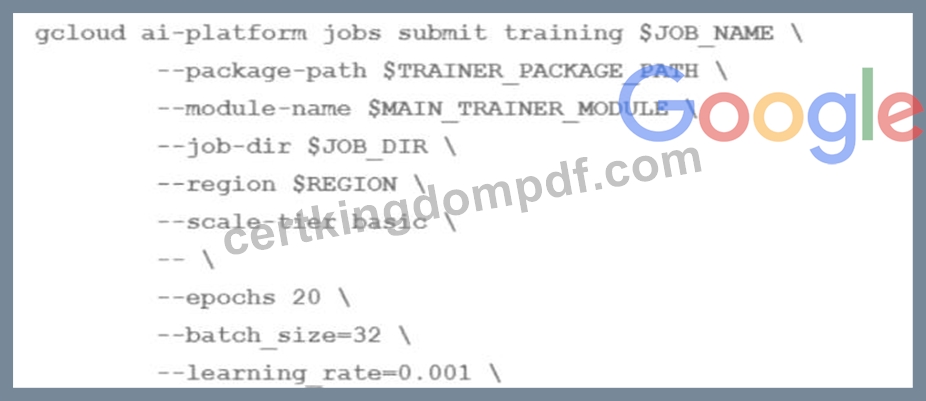
You want to ensure that training time is minimized without significantly compromising the accuracy of your model. What should you do?
- A. Modify the 'scale-tier' parameter
- B. Modify the 'learning rate' parameter
- C. Modify the 'epochs' parameter
- D. Modify the batch size' parameter
Answer: A
Explanation:
The training time of a machine learning model depends on several factors, such as the complexity of the model, the size of the data, the hardware resources, and the hyperparameters. To minimize the training time without significantly compromising the accuracy of the model, one should optimize these factors as much as possible.
One of the factors that can have a significant impact on the training time is the scale-tier parameter, which specifies the type and number of machines to use for the training job on AI Platform. The scale-tier parameter can be one of the predefined values, such as BASIC, STANDARD_1, PREMIUM_1, or BASIC_GPU, or a custom value that allows you to configure the machine type, the number of workers, and the number of parameter servers1 To speed up the training of an LSTM-based model on AI Platform, one should modify the scale-tier parameter to use a higher tier or a custom configuration that provides more computational resources, such as more CPUs, GPUs, or TPUs. This can reduce the training time by increasing the parallelism and throughput of the model training. However, one should also consider the trade-off between the training time and the cost, as higher tiers or custom configurations may incur higher charges2 The other options are not as effective or may have adverse effects on the model accuracy. Modifying the epochs parameter, which specifies the number of times the model sees the entire dataset, may reduce the training time, but also affect the model's convergence and performance. Modifying the batch size parameter, which specifies the number of examples per batch, may affect the model's stability and generalization ability, as well as the memory usage and the gradient update frequency. Modifying the learning rate parameter, which specifies the step size of the gradient descent optimization, may affect the model's convergence and performance, as well as the risk of overshooting or getting stuck in local minima3 References: 1: Using predefined machine types 2: Distributed training 3: Hyperparameter tuning overview
NEW QUESTION # 153
You recently deployed a pipeline in Vertex Al Pipelines that trains and pushes a model to a Vertex Al endpoint to serve real-time traffic. You need to continue experimenting and iterating on your pipeline to improve model performance. You plan to use Cloud Build for CI/CD You want to quickly and easily deploy new pipelines into production and you want to minimize the chance that the new pipeline implementations will break in production. What should you do?
- A. Set up a CI/CD pipeline that builds your source code and then deploys built artifacts into a pre-production environment Run unit tests in the pre-production environment If the tests are successful deploy the pipeline to production.
- B. Set up a CI/CD pipeline that builds and tests your source code and then deploys built artifacts into a pre-production environment. After a successful pipeline run in the pre-production environment deploy the pipeline to production
- C. Set up a CI/CD pipeline that builds and tests your source code and then deploys built arrets into a pre-production environment After a successful pipeline run in the pre-production environment, rebuild the source code, and deploy the artifacts to production
- D. Set up a CI/CD pipeline that builds and tests your source code If the tests are successful use the Google Cloud console to upload the built container to Artifact Registry and upload the compiled pipeline to Vertex Al Pipelines.
Answer: B
Explanation:
The best option for continuing experimenting and iterating on your pipeline to improve model performance, using Cloud Build for CI/CD, and deploying new pipelines into production quickly and easily, is to set up a CI/CD pipeline that builds and tests your source code and then deploys built artifacts into a pre-production environment. After a successful pipeline run in the pre-production environment, deploy the pipeline to production. This option allows you to leverage the power and simplicity of Cloud Build to automate, monitor, and manage your pipeline development and deployment workflow. Cloud Build is a service that can create and run continuous integration and continuous delivery (CI/CD) pipelines on Google Cloud. Cloud Build can build your source code, run unit tests, and deploy built artifacts to various Google Cloud services, such as Vertex AI Pipelines, Vertex AI Endpoints, and Artifact Registry. A CI/CD pipeline is a workflow that can automate the process of building, testing, and deploying software. A CI/CD pipeline can help you improve the quality and reliability of your software, accelerate the development and delivery cycle, and reduce the manual effort and errors. A pre-production environment is an environment that can simulate the production environment, but is isolated from the real users and data. A pre-production environment can help you test and validate your software before deploying it to production, and catch any bugs or issues that may affect the user experience or the system performance. By setting up a CI/CD pipeline that builds and tests your source code and then deploys built artifacts into a pre-production environment, you can ensure that your pipeline code is consistent and error-free, and that your pipeline artifacts are compatible and functional. After a successful pipeline run in the pre-production environment, you can deploy the pipeline to production, which is the environment where your software is accessible and usable by the real users and data. By deploying the pipeline to production after a successful pipeline run in the pre-production environment, you can minimize the chance that the new pipeline implementations will break in production, and ensure that your software meets the user expectations and requirements1.
The other options are not as good as option C, for the following reasons:
* Option A: Setting up a CI/CD pipeline that builds and tests your source code, and if the tests are successful, using the Google Cloud console to upload the built container to Artifact Registry and upload the compiled pipeline to Vertex AI Pipelines would not allow you to deploy new pipelines into production quickly and easily, and could increase the manual effort and errors. The Google Cloud console is a web-based user interface that can help you access and manage various Google Cloud services, such as Artifact Registry and Vertex AI Pipelines. Artifact Registry is a service that can store and manage your container images and other artifacts on Google Cloud. Artifact Registry can help you upload and organize your container images, and track the image versions and metadata. Vertex AI Pipelines is a service that can orchestrate machine learning workflows using Vertex AI. Vertex AI Pipelines can run preprocessing and training steps on custom Docker images, and evaluate, deploy, and monitor the machine learning model. However, setting up a CI/CD pipeline that builds and tests your source code, and if the tests are successful, using the Google Cloud console to upload the built container to Artifact Registry and upload the compiled pipeline to Vertex AI Pipelines would not allow you to deploy new pipelines into production quickly and easily, and could increase the manual effort and errors. You would need to write code, create and run the CI/CD pipeline, use the Google Cloud console to upload the built container to Artifact Registry, and use the Google Cloud console to upload the
* compiled pipeline to Vertex AI Pipelines. Moreover, this option would not use a pre-production environment to test and validate your pipeline before deploying it to production, which could increase the chance that the new pipeline implementations will break in production1.
* Option B: Setting up a CI/CD pipeline that builds your source code and then deploys built artifacts into a pre-production environment, running unit tests in the pre-production environment, and if the tests are successful, deploying the pipeline to production would not allowyou to test and validate your pipeline before deploying it to production, and could cause errors or poor performance. A unit test is a type of test that can verify the functionality and correctness of a small and isolated unit of code, such as a function or a class. A unit test can help you debug and improve your code quality, and catch any bugs or issues that may affect the code logic or output. However, setting up a CI/CD pipeline that builds your source code and then deploys built artifacts into a pre-production environment, running unit tests in the pre-production environment, and if the tests are successful, deploying the pipeline to production would not allow you to test and validate your pipeline before deploying it to production, and could cause errors or poor performance. You would need to write code, create and run the CI/CD pipeline, deploy the built artifacts to the pre-production environment, run the unit tests in the pre-production environment, and deploy the pipeline to production. Moreover, this option would not run the pipeline in the pre-production environment, which could prevent you from testing and validating the pipeline functionality and compatibility, and catching any bugs or issues that may affect the pipeline workflow or output1.
* Option D: Setting up a CI/CD pipeline that builds and tests your source code and then deploys built artifacts into a pre-production environment, after a successful pipeline run in the pre-production environment, rebuilding the source code, and deploying the artifacts to production would not allow you to deploy new pipelines into production quickly and easily, and could increase the complexity and cost of the pipeline development and deployment. Rebuilding the source code is a process that can recompile and repackage the source code into executable artifacts, such as container images and pipeline files.
Rebuilding the source code can help you incorporate any changes or updates that may have occurred in the source code, and ensure that the artifacts are consistent and up-to-date. However, setting up a CI/CD pipeline that builds and tests your source code and then deploys built artifacts into a pre-production environment, after a successful pipeline run in the pre-production environment, rebuilding the source code, and deploying the artifacts to production would not allow you to deploy new pipelines into production quickly and easily, and could increase the complexity and cost of the pipeline development and deployment. You would need to write code, create and run the CI/CD pipeline, deploy the built artifacts to the pre-production environment, run the pipeline in the pre-production environment, rebuild the source code, and deploy the artifacts to production. Moreover, this option would increase the pipeline development and deployment time, as rebuilding the source code can be a time-consuming and resource-intensive process1.
References:
* Preparing for Google Cloud Certification: Machine Learning Engineer, Course 3: Production ML Systems, Week 3: MLOps
* Google Cloud Professional Machine Learning Engineer Exam Guide, Section 3: Scaling ML models in production, 3.2 Automating ML workflows
* Official Google Cloud Certified Professional Machine Learning Engineer Study Guide, Chapter 6:
Production ML Systems, Section 6.4: Automating ML Workflows
* Cloud Build
* Vertex AI Pipelines
* Artifact Registry
* Pre-production environment
NEW QUESTION # 154
An agency collects census information within a country to determine healthcare and social program needs by province and city. The census form collects responses for approximately 500 questions from each citizen.
Which combination of algorithms would provide the appropriate insights? (Choose two.)
- A. The Latent Dirichlet Allocation (LDA) algorithm
- B. The factorization machines (FM) algorithm
- C. The k-means algorithm
- D. The Random Cut Forest (RCF) algorithm
- E. The principal component analysis (PCA) algorithm
Answer: C,E
Explanation:
Explanation/Reference:
Explanation:
The PCA and K-means algorithms are useful in collection of data using census form.
NEW QUESTION # 155
You work at a bank You have a custom tabular ML model that was provided by the bank's vendor. The training data is not available due to its sensitivity. The model is packaged as a Vertex Al Model serving container which accepts a string as input for each prediction instance. In each string the feature values are separated by commas. You want to deploy this model to production for online predictions, and monitor the feature distribution over time with minimal effort What should you do?
- A. 1 Upload the model to Vertex Al Model Registry and deploy the model to a Vertex Al endpoint.
2 Create a Vertex Al Model Monitoring job with feature skew detection as the monitoring objective and provide an instance schema. - B. 1 Refactor the serving container to accept key-value pairs as input format.
2. Upload the model to Vertex Al Model Registry and deploy the model to a Vertex Al endpoint.
3. Create a Vertex Al Model Monitoring job with feature drift detection as the monitoring objective. - C. 1 Upload the model to Vertex Al Model Registry and deploy the model to a Vertex Ai endpoint.
2. Create a Vertex Al Model Monitoring job with feature drift detection as the monitoring objective, and provide an instance schema. - D. 1 Refactor the serving container to accept key-value pairs as input format.
2 Upload the model to Vertex Al Model Registry and deploy the model to a Vertex Al endpoint.
3. Create a Vertex Al Model Monitoring job with feature skew detection as the monitoring objective.
Answer: B
NEW QUESTION # 156
You have a functioning end-to-end ML pipeline that involves tuning the hyperparameters of your ML model using Al Platform, and then using the best-tuned parameters for training. Hypertuning is taking longer than expected and is delaying the downstream processes. You want to speed up the tuning job without significantly compromising its effectiveness. Which actions should you take?
Choose 2 answers
- A. Change the search algorithm from Bayesian search to random search.
- B. Decrease the maximum number of trials during subsequent training phases.
- C. Decrease the number of parallel trials
- D. Decrease the range of floating-point values
- E. Set the early stopping parameter to TRUE
Answer: B,E
Explanation:
Hyperparameter tuning is the process of finding the optimal values for the parameters of a machine learning model that affect its performance. AI Platform provides a service for hyperparameter tuning that can run multiple trials in parallel and use different search algorithms to find the best combination of hyperparameters.
However, hyperparameter tuning can be time-consuming and costly, especially if the search space is large and the model training is complex. Therefore, it is important to optimize the tuning job to reduce the time and resources required.
One way to speed up the tuning job is to set the early stopping parameter to TRUE. This means that the tuning service will automatically stop trials that are unlikely to perform well based on the intermediate results. This can save time and resources by avoiding unnecessary computations for trials that are not promising. The early stopping parameter can be set in the trainingInput.hyperparameters field of the training job request1 Another way to speed up the tuning job is to decrease the maximum number of trials during subsequent training phases. This means that the tuning service will use fewer trials to refine the search space after the initial phase. This can reduce the time required for the tuning job to converge to the optimal solution. The maximum number of trials can be set in the trainingInput.hyperparameters.maxTrials field of the training job request1 The other options are not effective ways to speed up the tuning job. Decreasing the number of parallel trials will reduce the concurrency of the tuning job and increase the overall time required. Decreasing the range of floating-point values will reduce the diversity of the search space and may miss some optimal solutions. Changing the search algorithm from Bayesian search to random search will reduce the efficiency of the tuning job and may require more trials to find the best solution1 References: 1: Hyperparameter tuning overview
NEW QUESTION # 157
You built and manage a production system that is responsible for predicting sales numbers. Model accuracy is crucial, because the production model is required to keep up with market changes. Since being deployed to production, the model hasn't changed; however the accuracy of the model has steadily deteriorated. What issue is most likely causing the steady decline in model accuracy?
- A. Poor data quality
- B. Incorrect data split ratio during model training, evaluation, validation, and test
- C. Too few layers in the model for capturing information
- D. Lack of model retraining
Answer: D
Explanation:
Model retraining is the process of updating an existing machine learning model with new data and parameters to improve its performance and accuracy. Model retraining is essential for maintaining the relevance and validity of the model, especially when the data or the environment changes over time. Model retraining can help to avoid or reduce the effects of model degradation, which is the phenomenon of the model's predictive performance decreasing as it is tested on new datasets within rapidly evolving environments1.
For the use case of predicting sales numbers, model accuracy is crucial, because the production model is required to keep up with market changes. Market changes can affect the demand, supply, price, and preference of the products, and thus influence the sales numbers. If the model is not retrained with new data that reflects the market changes, it may become outdated and inaccurate, and fail to capture the patterns and trends of the sales numbers. Therefore, the most likely issue that is causing the steady decline in model accuracy is the lack of model retraining.
The other options are not as likely as option B, because they are not directly related to the model's ability to adapt to market changes. Option A, poor data quality, may affect the model's accuracy, but it is not a specific cause of model degradation over time. Option C, too few layers in the model for capturing information, may affect the model's complexity and expressiveness, but it is not a specific cause of model degradation over time. Option D, incorrect data split ratio during model training, evaluation, validation, and test, may affect the model's generalization and validation, but it is not a specific cause of model degradation over time. Therefore, option B, lack of model retraining, is the best answer for this question.
References:
* Beware Steep Decline: Understanding Model Degradation In Machine Learning Models
NEW QUESTION # 158
You work at a large organization that recently decided to move their ML and data workloads to Google Cloud. The data engineering team has exported the structured data to a Cloud Storage bucket in Avro format. You need to propose a workflow that performs analytics, creates features, and hosts the features that your ML models use for online prediction How should you configure the pipeline?
- A. Ingest the Avro files into Cloud Spanner to perform analytics Use a Dataflow pipeline to create the features and store them in BigQuery for online prediction.
- B. Ingest the Avro files into BigQuery to perform analytics Use a Dataflow pipeline to create the features, and store them in Vertex Al Feature Store for online prediction.
- C. Ingest the Avro files into Cloud Spanner to perform analytics. Use a Dataflow pipeline to create the features. and store them in Vertex Al Feature Store for online prediction.
- D. Ingest the Avro files into BigQuery to perform analytics Use BigQuery SQL to create features and store them in a separate BigQuery table for online prediction.
Answer: B
NEW QUESTION # 159
You want to rebuild your ML pipeline for structured data on Google Cloud. You are using PySpark to conduct data transformations at scale, but your pipelines are taking over 12 hours to run. To speed up development and pipeline run time, you want to use a serverless tool and SQL syntax. You have already moved your raw data into Cloud Storage. How should you build the pipeline on Google Cloud while meeting the speed and processing requirements?
- A. Ingest your data into Cloud SQL convert your PySpark commands into SQL queries to transform the data, and then use federated queries from BigQuery for machine learning
- B. Ingest your data into BigQuery using BigQuery Load, convert your PySpark commands into BigQuery SQL queries to transform the data, and then write the transformations to a new table
- C. Convert your PySpark into SparkSQL queries to transform the data and then run your pipeline on Dataproc to write the data into BigQuery.
- D. Use Data Fusion's GUI to build the transformation pipelines, and then write the data into BigQuery
Answer: B
Explanation:
BigQuery is a serverless, scalable, and cost-effective data warehouse that allows users to run SQL queries on large volumes of data. BigQuery Load is a tool that can ingest data from Cloud Storage into BigQuery tables.
BigQuery SQL is a dialect of SQL that supports many of the same functions and operations as PySpark, such as window functions, aggregate functions, joins, and subqueries. By using BigQuery Load and BigQuery SQL, you can rebuild your ML pipeline for structured data on Google Cloud without having to manage any servers or clusters, and with faster performance and lower cost than using PySpark on Dataproc. You can also use BigQuery ML to create and evaluate ML models using SQL commands. References:
* BigQuery documentation
* BigQuery Load documentation
* BigQuery SQL reference
* BigQuery ML documentation
NEW QUESTION # 160
You developed a custom model by using Vertex Al to predict your application's user churn rate You are using Vertex Al Model Monitoring for skew detection The training data stored in BigQuery contains two sets of features - demographic and behavioral You later discover that two separate models trained on each set perform better than the original model You need to configure a new model mentioning pipeline that splits traffic among the two models You want to use the same prediction-sampling-rate and monitoring-frequency for each model You also want to minimize management effort What should you do?
- A. Separate the training dataset into two tables based on demographic and behavioral features. Deploy both models to the same endpoint and submit a Vertex Al Model Monitoring job with a monitoring-config-from parameter that accounts for the model IDs and training datasets
- B. Keep the training dataset as is Deploy the models to two separate endpoints and submit two Vertex Al Model Monitoring jobs with appropriately selected feature-thresholds parameters
- C. Separate the training dataset into two tables based on demographic and behavioral features Deploy the models to two separate endpoints, and submit two Vertex Al Model Monitoring jobs
- D. Keep the training dataset as is Deploy both models to the same endpoint and submit a Vertex Al Model Monitoring job with a monitoring-config-from parameter that accounts for the model IDs and feature selections
Answer: D
NEW QUESTION # 161
Your work for a textile manufacturing company. Your company has hundreds of machines and each machine has many sensors. Your team used the sensory data to build hundreds of ML models that detect machine anomalies Models are retrained daily and you need to deploy these models in a cost-effective way. The models must operate 24/7 without downtime and make sub millisecond predictions. What should you do?
- A. Deploy a Dataflow streaming pipeline with the Runlnference API and use automatic model refresh.
- B. Deploy a Dataflow batch pipeline and a Vertex Al Prediction endpoint.
- C. Deploy a Dataflow streaming pipeline and a Vertex Al Prediction endpoint with autoscaling.
- D. Deploy a Dataflow batch pipeline with the Runlnference API. and use model refresh.
Answer: A
NEW QUESTION # 162
You have recently used TensorFlow to train a classification model on tabular data You have created a Dataflow pipeline that can transform several terabytes of data into training or prediction datasets consisting of TFRecords. You now need to productionize the model, and you want the predictions to be automatically uploaded to a BigQuery table on a weekly schedule. What should you do?
- A. Import the model into BigQuery Implement the data processing logic in a SQL query On Vertex Al Pipelines create a pipeline that uses the BigqueryQueryJobop and the EigqueryPredictModejobOp components.
- B. Import the model into Vertex Al and deploy it to a Vertex Al endpoint Create a Dataflow pipeline that reuses the data processing logic sends requests to the endpoint and then uploads predictions to a BigQuery table.
- C. Import the model into Vertex Al and deploy it to a Vertex Al endpoint On Vertex Al Pipelines create a pipeline that uses the Dataf lowPythonJobop and the Mcdei3archPredictoc components.
- D. Import the model into Vertex Al On Vertex Al Pipelines, create a pipeline that uses the DatafIowPythonJobOp and the ModelBatchPredictOp components.
Answer: D
Explanation:
Vertex AI is a service that allows you to create and train ML models using Google Cloud technologies. You can use Vertex AI to import the model that you trained with TensorFlow and store it in theVertex AI Model Registry. The Vertex AI Model Registry is a service that allows you to store and manage your ML models on Google Cloud. You can then use Vertex AI Pipelines to create a pipeline that uses the DataflowPythonJobOp and the ModelBatchPredictOp components. The DataflowPythonJobOp component is a component that allows you to run a Dataflow job using a Python script. Dataflow is a service that allows you to create and run scalable and portable data processing pipelines on Google Cloud. You can use the DataflowPythonJobOp component to reuse the data processing logic that you created for transforming the data into TFRecords. The ModelBatchPredictOp component is a component that allows you to run a batch prediction job using a model from the Vertex AI Model Registry. Batch prediction is a type of prediction that provides high-throughput responses to large batches of input data. You can use the ModelBatchPredictOp component to make predictions using the TFRecords from the DataflowPythonJobOp component and the model from the Vertex AI Model Registry. You can also configure the ModelBatchPredictOp component to automatically upload the predictions to a BigQuery table. BigQuery is a service that allows you to store and query large amounts of data in a scalable and cost-effective way. You can use BigQuery to store and analyze the predictions from your model. You can also schedule the pipeline to run on a weekly basis, so that the predictions are updated regularly. By using Vertex AI, Vertex AI Pipelines, Dataflow, and BigQuery, you can productionize the model and upload the predictions to a BigQuery table on a weekly schedule. References:
* Vertex AI documentation
* Vertex AI Pipelines documentation
* Dataflow documentation
* BigQuery documentation
* Preparing for Google Cloud Certification: Machine Learning Engineer Professional Certificate
NEW QUESTION # 163
......
Latest 100% Passing Guarantee - Brilliant Professional-Machine-Learning-Engineer Exam Questions PDF: https://www.certkingdompdf.com/Professional-Machine-Learning-Engineer-latest-certkingdom-dumps.html
Practice Examples and Dumps & Tips for 2024 Latest Professional-Machine-Learning-Engineer Valid Tests Dumps: https://drive.google.com/open?id=1GyMSVeIfBQEMq3RWts0dD0ChwR5ymkun